
Το πρώτο «μοντέλο συλλογισμού» στον κόσμο, μια προηγμένη μορφή τεχνητής νοημοσύνης, κυκλοφόρησε τον Σεπτέμβριο από την αμερικανική εταιρεία OpenAI. Το o1, όπως ονομάζεται, χρησιμοποιεί μια «αλυσίδα σκέψης» για να απαντήσει σε δύσκολα ερωτήματα στις επιστήμες και τα μαθηματικά, αναλύοντας τα προβλήματα στα συστατικά τους βήματα και δοκιμάζοντας διάφορες προσεγγίσεις του ερωτήματος στο παρασκήνιο πριν παρουσιάσει το συμπέρασμα στον χρήστη. Η αποκάλυψή του πυροδότησε έναν αγώνα δρόμου για την αντιγραφή του. Η Google παρουσίασε τον Δεκέμβριο ένα μοντέλο συλλογισμού με την ονομασία «Gemini Flash Thinking». Λίγες ημέρες αργότερα, η OpenAI απάντησε με το o3, μια αναβάθμιση του o1.
Ωστόσο η Google, με όλους τους πόρους της, δεν ήταν η πρώτη εταιρεία που μιμήθηκε την OpenAI. Λιγότερο από τρεις μήνες μετά την κυκλοφορία του o1, η Alibaba, ο κινεζικός γίγαντας του ηλεκτρονικού εμπορίου, κυκλοφόρησε μια νέα έκδοση του chatbot Qwen, το QwQ, με τις ίδιες δυνατότητες «συλλογισμού». «Τι σημαίνει να σκέφτεσαι, να αναρωτιέσαι, να καταλαβαίνεις;», διερωτήθηκε η εταιρεία σε μια εξεζητημένα διατυπωμένη ανάρτηση στο ιστολόγιο με έναν σύνδεσμο που έδινε πρόσβαση στη δωρεάν έκδοση του μοντέλου. Μία εβδομάδα πιο πριν, μια άλλη κινεζική εταιρεία, η DeepSeek, είχε κυκλοφορήσει μια «προεπισκόπηση» ενός μοντέλου συλλογισμού, με την ονομασία R1. Παρά τις προσπάθειες της αμερικανικής κυβέρνησης να συγκρατήσει την κινεζική βιομηχανία τεχνητής νοημοσύνης, δύο κινεζικές εταιρείες κατόρθωσαν να μειώσουν το τεχνολογικό προβάδισμα των Αμερικανών ομολόγων τους σε λίγες εβδομάδες.
Οι κινεζικές εταιρείες δεν πρωτοπορούν μόνο στα μοντέλα συλλογισμού: τον Δεκέμβριο η DeepSeek παρουσίασε ένα νέο μεγάλο γλωσσικό μοντέλο (LLM), μια μορφή τεχνητής νοημοσύνης που αναλύει και παράγει κείμενο. Το v3 ήταν σχεδόν 700 gigabytes, πολύ μεγάλο για να τρέξει σε οτιδήποτε άλλο εκτός από εξειδικευμένο υλικό, και είχε 685 δισ. παραμέτρους, τις επιμέρους εντολές που συνδυάζονται για να σχηματίσουν το νευρωνικό δίκτυο του μοντέλου, καθιστώντας το μεγαλύτερο από οτιδήποτε άλλο είχε κυκλοφορήσει προηγουμένως για δωρεάν λήψη. Το Llama 3.1, η ναυαρχίδα των LLM της Meta, της μητρικής εταιρείας του Facebook, που κυκλοφόρησε τον Ιούλιο, έχει μόνο 405 δισεκατομμύρια παραμέτρους.
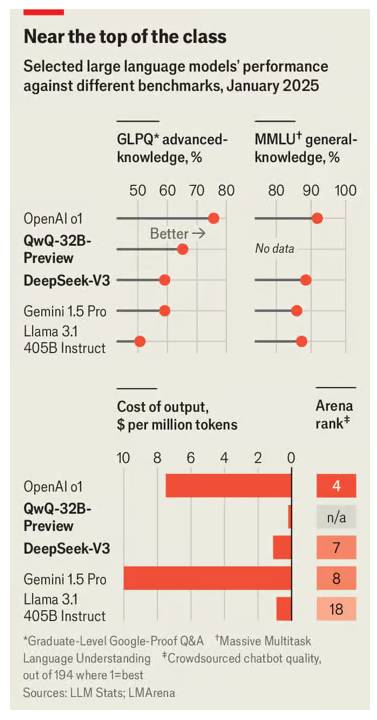
Το LLM της DeepSeek δεν είναι μόνο μεγαλύτερο από πολλά από τα αντίστοιχα δυτικά μοντέλα, είναι και καλύτερο, καθώς συγκρίνεται μόνο με τα ιδιόκτητα μοντέλα της Google και της OpenAI. Ο Paul Gauthier, ιδρυτής της Aider, μιας πλατφόρμας κωδικοποίησης τεχνητής νοημοσύνης, έτρεξε το νέο μοντέλο DeepSeek στο δικό του μέτρο σύγκρισης κωδικοποίησης και διαπίστωσε ότι ξεπέρασε όλους τους αντιπάλους του, εκτός από το o1. Το Lmsys, μια κατάταξη chatbots από το πλήθος, το τοποθετεί στην έβδομη θέση, υψηλότερα από οποιοδήποτε άλλο μοντέλο ανοιχτού κώδικα και την υψηλότερη για μοντέλο που έχει παραχθεί από εταιρεία εκτός της Google ή της OpenAI (βλ. διάγραμμα).
Η είσοδος του δράκου
Η κινεζική τεχνητή νοημοσύνη είναι πλέον τόσο κοντά σε ποιότητα με αυτή των Αμερικανών αντιπάλων της, ώστε το αφεντικό της OpenAI, ο Sam Altman, αισθάνθηκε υποχρεωμένος να εξηγήσει αυτή τη μείωση του χάσματος. Λίγο αφότου η DeepSeek κυκλοφόρησε τo v3, έγραψε σκωπτικά στο Twitter: «Είναι (σχετικά) εύκολο να αντιγράψεις κάτι που ξέρεις ότι λειτουργεί. Το δύσκολο είναι να κάνεις κάτι νέο, ριψοκίνδυνο και δύσκολο όταν δεν ξέρεις αν θα λειτουργήσει».
Η βιομηχανία της τεχνητής νοημοσύνης της Κίνας είχε αρχικά εμφανιστεί ως δευτερεύουσας σημασίας. Αυτό μπορεί να οφείλεται εν μέρει στο γεγονός ότι είχε να διαχειριστεί τις αμερικανικές κυρώσεις. Το 2022 η Αμερική απαγόρευσε την εξαγωγή προηγμένων τσιπ στην Κίνα. Η Nvidia, κορυφαία κατασκευάστρια τσιπ, αναγκάστηκε να σχεδιάσει ειδικά υποβαθμισμένα προϊόντα για την κινεζική αγορά. Η Αμερική προσπάθησε επίσης να αποτρέψει την Κίνα από το να αναπτύξει την ικανότητα να κατασκευάζει κορυφαία τσιπ στο εσωτερικό της, απαγορεύοντας τις εξαγωγές του απαραίτητου εξοπλισμού και απειλώντας με κυρώσεις τις μη αμερικανικές εταιρείες που θα μπορούσαν να τη βοηθήσουν.
Ένα άλλο εμπόδιο είναι εγχώριο. Οι κινεζικές εταιρείες άργησαν να εκμεταλλευτούν τα LLMs, εν μέρει λόγω ρυθμιστικών ανησυχιών. Ανησυχούσαν για το πώς θα αντιδρούσε η λογοκρισία σε μοντέλα που μπορεί να μην αντικατοπτρίζουν την πραγματικότητα και να παρέχουν λανθασμένες πληροφορίες ή -ακόμα χειρότερα- να καταλήγουν σε πολιτικά επικίνδυνες δηλώσεις. Η Baidu, ένας γίγαντας αναζήτησης, πειραματιζόταν με LLMs εσωτερικά για χρόνια και είχε δημιουργήσει ένα με την ονομασία «ERNIE», αλλά δίσταζε να το δώσει στο κοινό. Ακόμα και όταν η επιτυχία του ChatGPT την ώθησε να το ξανασκεφτεί, στην αρχή επέτρεψε την πρόσβαση στο ERNIEbot μόνο κατόπιν προσκλήσεως.
Τελικά οι κινεζικές αρχές εξέδωσαν κανονισμούς για την προώθηση της τεχνητής νοημοσύνης. Αν και κάλεσαν τους κατασκευαστές μοντέλων να δώσουν έμφαση στο υγιές περιεχόμενο και να τηρήσουν τις «σοσιαλιστικές αξίες», δεσμεύτηκαν επίσης να «ενθαρρύνουν την καινοτόμο ανάπτυξη της δημιουργικής ΤΝ». Η Κίνα επεδίωξε να ανταγωνιστεί σε παγκόσμιο επίπεδο, λέει η Vivian Toh, συντάκτρια του ειδησεογραφικού ιστότοπου TechTechChina. Η Alibaba ήταν μία από τις πρώτες εταιρείες που προσαρμόστηκαν στο νέο επιτρεπτικό περιβάλλον, εγκαινιάζοντας το δικό της LLM, που αρχικά ονομάστηκε Tongyi Qianwen και αργότερα μετονομάστηκε για συντομία σε «Qwen».
Για ένα χρόνο περίπου, αυτό που παρήγαγε η Alibaba δεν ήταν κάτι συνταρακτικό: ένα αρκετά αδιάφορο μοντέλο βασισμένο στο Llama LLM ανοιχτού κώδικα της Meta. Αλλά κατά τη διάρκεια του 2024, καθώς η Alibaba κυκλοφόρησε διαδοχικές επαναλήψεις του Qwen, η ποιότητα άρχισε να βελτιώνεται. «Αυτά τα μοντέλα φαίνεται να ανταγωνίζονται ισχυρά μοντέλα κορυφαίων εργαστηρίων της Δύσης», δήλωσε πριν από ένα χρόνο, ο Jack Clark της Anthropic, ενός δυτικού εργαστηρίου τεχνητής νοημοσύνης, όταν η Alibaba κυκλοφόρησε μια έκδοση του Qwen με δυνατότητα να αναλύει τόσο εικόνες όσο και κείμενο.
Οι άλλοι γίγαντες του διαδικτύου της Κίνας, όπως η Tencent και η Huawei, δημιουργούν τα δικά τους μοντέλα. Ωστόσο η DeepSeek έχει διαφορετική προέλευση. Δεν υπήρχε καν όταν η Alibaba κυκλοφόρησε το πρώτο μοντέλο Qwen. Προέρχεται από το High-Flyer, ένα hedge fund που δημιουργήθηκε το 2015 για να χρησιμοποιήσει την τεχνητή νοημοσύνη ώστε να αποκτήσει πλεονέκτημα στις συναλλαγές μετοχών. Η διεξαγωγή θεμελιωδών ερευνών βοήθησε το High-Flyer να γίνει ένα από τα μεγαλύτερα quant funds στη χώρα.
Βέβαια, σύμφωνα με τον Liang Wenfeng, ιδρυτή του High-Flyer, το κίνητρο δεν ήταν καθαρά εμπορικό. Οι πρώτοι χρηματοδότες της OpenAI δεν αναζητούσαν κέρδος, παρατήρησε. Το κίνητρό τους ήταν να «διεκπεραιώσουν την αποστολή». Το 2023,τον ίδιο μήνα που ξεκίνησε το Qwen, η High-Flyer ανακοίνωσε ότι και αυτή έμπαινε στη κούρσα για τη δημιουργία τεχνητής νοημοσύνης ανθρώπινου επιπέδου και διαχώρισε την ερευνητική μονάδα τεχνητής νοημοσύνης της ονομάζοντάς την DeepSeek.
Όπως και η OpenAI πριν από αυτή, έτσι και η DeepSeek υποσχέθηκε να αναπτύξει την τεχνητή νοημοσύνη για το δημόσιο καλό. Η εταιρεία θα δημοσιοποιήσει τα περισσότερα από τα αποτελέσματα της εκπαίδευσής της, δήλωσε ο κ. Liang, για να προσπαθήσει να αποτρέψει τη «μονοπώληση» της τεχνολογίας από λίγα μόνο άτομα ή επιχειρήσεις. Σε αντίθεση με την OpenAI, η οποία αναγκάστηκε να αναζητήσει ιδιωτική χρηματοδότηση για να καλύψει το διογκούμενο κόστος εκπαίδευσης, η DeepSeek είχε πάντοτε πρόσβαση στα τεράστια αποθέματα υπολογιστικής ισχύος του High-Flyer.
Το γιγαντιαίο LLM της DeepSeek είναι αξιοσημείωτο όχι μόνο για την κλίμακά του, αλλά και για την αποτελεσματικότητα της εκπαίδευσής του, κατά την οποία το μοντέλο τροφοδοτείται με δεδομένα από τα οποία διαμορφώνει τις παραμέτρους του. Αυτή η επιτυχία δεν προήλθε από μια μοναδική, μεγάλη καινοτομία, λέει ο Nic Lane του Πανεπιστημίου του Cambridge, αλλά από μια σειρά οριακών βελτιώσεων. Η διαδικασία εκπαίδευσης, για παράδειγμα, χρησιμοποιούσε συχνά στρογγυλοποιήσεις για να διευκολύνει τους υπολογισμούς, αλλά όταν ήταν απαραίτητο, διατηρούσε τους αριθμούς ακριβείς. Η φάρμα διακομιστών αναδιαμορφώθηκε έτσι ώστε τα μεμονωμένα τσιπ να μιλούν μεταξύ τους πιο αποτελεσματικά. Επιπλέον, μετά την εκπαίδευση του, το μοντέλο τελειοποιήθηκε ως προς την παραγωγή από το DeepSeek R1, το σύστημα συλλογισμού, μαθαίνοντας να μιμείται την ποιότητά του με χαμηλότερο κόστος.
Χάρη σε αυτές και σε άλλες καινοτομίες, για την διαμόρφωση των δισεκατομμυρίων παραμέτρων του v3 χρειάστηκαν λιγότερες από 3 εκατομμύρια ώρες με τσιπ, με εκτιμώμενο κόστος λιγότερο από 6 εκατομμύρια δολάρια – περίπου το ένα δέκατο της υπολογιστικής ισχύος και των εξόδων που απαιτήθηκαν για την κατάρτιση του Llama 3.1. Η εκπαίδευση του v3 απαίτησε μόλις 2.000 τσιπ, ενώ το Llama 3.1 χρησιμοποίησε 16.000. Και λόγω των αμερικανικών κυρώσεων, τα τσιπ που χρησιμοποίησε το v3 δεν ήταν καν τα πιο ισχυρά. Οι δυτικές επιχειρήσεις φαίνονται όλο και πιο σπάταλες με τα τσιπ: Η Meta σχεδιάζει να κατασκευάσει μια φάρμα διακομιστών χρησιμοποιώντας 350.000. Όπως η Ginger Rogers χορεύει ανορθόδοξα και με ψηλά τακούνια, η DeepSeek, λέει ο Andrej Karpathy, πρώην επικεφαλής της του τμήματος ΤΝ στην Tesla, έκανε την εκπαίδευση ενός περιφερειακού μοντέλου «με έναν αστείο προϋπολογισμό, να φαίνεται «εύκολη».
Το μοντέλο όχι μόνο εκπαιδεύτηκε φθηνά, αλλά και η λειτουργία του κοστίζει λιγότερο. Η DeepSeek κατανέμει τις εργασίες σε πολλαπλά τσιπ πιο αποτελεσματικά από ό,τι οι ομότιμές της και, πριν ολοκληρωθεί το προηγούμενο, ξεκινά το επόμενο βήμα της διαδικασίας. Αυτό της επιτρέπει να διατηρεί τα τσιπ σε πλήρη δυναμικότητα με ελάχιστο πλεονασμό. Ως αποτέλεσμα, τον Φεβρουάριο, όταν η DeepSeek θα αρχίσει να επιτρέπει σε άλλες επιχειρήσεις να δημιουργούν υπηρεσίες που κάνουν χρήση της v3, θα χρεώνει λιγότερο από το ένα δέκατο αυτού που χρεώνει η Anthropic για τη χρήση του Claude, του LLM της. «Εάν τα μοντέλα είναι πράγματι ισοδύναμης ποιότητας, πρόκειται για μια δραματική νέα τροπή στον συνεχιζόμενο πόλεμο τιμολόγησης των LLM», λέει ο Simon Willison, ειδικός σε θέματα τεχνητής νοημοσύνης.
Η αναζήτηση της DeepSeek για αποδοτικότητα δεν σταμάτησε εκεί. Αυτή την εβδομάδα, αμέσως μετά την κυκλοφορία το R1 στο σύνολό του, κυκλοφόρησε επίσης μια σειρά από μικρότερες, φθηνότερες και ταχύτερες «σύνθετες» παραλλαγές, οι οποίες είναι σχεδόν εξίσου ισχυρές με το μεγαλύτερο μοντέλο. Με άλλα λόγια, μιμήθηκε παρόμοιες κυκλοφορίες από την Alibaba και τη Meta και απέδειξε για άλλη μια φορά ότι μπορεί να ανταγωνιστεί τα μεγαλύτερα ονόματα του κλάδου.
Ο δρόμος του δράκου
Η Alibaba και η DeepSeek αμφισβητούν τα πιο προηγμένα δυτικά εργαστήρια και με έναν άλλο τρόπο. Σε αντίθεση με την OpenAI και τη Google, τα κινεζικά εργαστήρια ακολουθούν το παράδειγμα της Meta και διαθέτουν τα συστήματά τους με άδεια χρήσης ανοικτού κώδικα. Αν θέλετε να κατεβάσετε το Qwen ΑΙ και να δημιουργήσετε τον δικό σας προγραμματισμό πάνω σε αυτό, μπορείτε, – δεν απαιτείται ειδική άδεια. Αυτή η ανεκτικότητα συνδυάζεται με μια αξιοσημείωτη διαφάνεια: οι δύο εταιρείες δημοσιεύουν έγγραφα κάθε φορά που κυκλοφορούν νέα μοντέλα που παρέχουν πλήθος λεπτομερειών σχετικά με τις τεχνικές που χρησιμοποιούνται για τη βελτίωση των επιδόσεών τους.
Όταν η Alibaba κυκλοφόρησε το QwQ, που σημαίνει «Questions with Qwen», έγινε η πρώτη εταιρεία στον κόσμο που δημοσίευσε ένα τέτοιο μοντέλο με ανοιχτή άδεια χρήσης, επιτρέποντας σε οποιονδήποτε να κατεβάσει ολόκληρο το αρχείο των 20 gigabyte και να το τρέξει στα δικά του συστήματα ή να το διαλύσει για να δει πώς λειτουργεί. Αυτή είναι μια αισθητά διαφορετική προσέγγιση από την OpenAI, η οποία κρατά κρυφές τις εσωτερικές λειτουργίες του o1.
Σε γενικές γραμμές, και τα δύο μοντέλα εφαρμόζουν αυτό που είναι γνωστό ως «test-time compute»: αντί να συγκεντρώνουν τη χρήση της υπολογιστικής ισχύος κατά τη διάρκεια της εκπαίδευσης του μοντέλου,όπως οι προηγούμενες γενιές LLM, καταναλώνουν πολύ περισσότερη κατά την απάντηση των ερωτημάτων. Πρόκειται για μια ψηφιακή εκδοχή αυτού που ο ψυχολόγος Daniel Kahneman ονόμασε «σκέψη τύπου δύο»: πιο αργή, πιο σκόπιμη και πιο αναλυτική από τη γρήγορη και ενστικτώδη «τύπου ένα», η οποία έχει αποφέρει πολλά υποσχόμενα αποτελέσματα σε τομείς όπως τα μαθηματικά και ο προγραμματισμός.
Αν σας τεθεί ένα απλό ερώτημα που αφορά γεγονότα – για παράδειγμα, να αναφέρετε την πρωτεύουσα της Γαλλίας – πιθανότατα θα απαντήσετε με την πρώτη λέξη που θα σας έρθει στο μυαλό, και πιθανότατα θα είναι σωστή. Ένα τυπικό chatbot λειτουργεί με τον ίδιο τρόπο: αν η στατιστική του αναπαράσταση της γλώσσας δίνει μια συντριπτικά προτιμώμενη απάντηση, συμπληρώνει την πρόταση αναλόγως.
Αν όμως σας τεθεί ένα πιο σύνθετο ερώτημα, έχετε την τάση να το σκέφτεστε με πιο δομημένο τρόπο. Αν σας ζητηθεί να αναφέρετε την πέμπτη πολυπληθέστερη πόλη της Γαλλίας, πιθανότατα θα ξεκινήσετε με μια μακρά λίστα μεγάλων γαλλικών πόλεων, στη συνέχεια θα προσπαθήσετε να τις ταξινομήσετε με βάση τον πληθυσμό τους και μετά θα δώσετε την απάντηση.
Το σκεπτικό για το o1 και τους μιμητές του είναι να παρακινήσουν ένα LLM να εμπλακεί στην ίδια μορφή δομημένης σκέψης: αντί να απαντά δίνοντας την πιο προφανή απάντηση που του έρχεται στο μυαλό, το σύστημα αναλύει το πρόβλημα και φτάνει στην απάντηση βήμα βήμα.
Όμως το o1 κρατάει τις σκέψεις του για τον εαυτό του, αποκαλύπτοντας στους χρήστες μόνο μια περίληψη της διαδικασίας και το τελικό συμπέρασμά του. Η OpenAI επικαλέστηκε κάποιες δικαιολογίες γι’ αυτή την επιλογή. Μερικές φορές, για παράδειγμα, το μοντέλο θα σκεφτεί αν πρέπει να χρησιμοποιήσει προσβλητικές λέξεις ή να αποκαλύψει επικίνδυνες πληροφορίες, αλλά στη συνέχεια θα αποφασίσει να μην το κάνει. Αν το πλήρες σκεπτικό του αποκαλυφθεί, τότε θα αποκαλυφθεί και το ευαίσθητο υλικό. Αλλά η επιφυλακτικότητα του μοντέλου κρατά επίσης κρυμμένους τους ακριβείς μηχανισμούς της συλλογιστικής του από τους επίδοξους αντιγραφείς.
Η Alibaba δεν έχει τέτοιους ενδοιασμούς. Ζητήστε από το QwQ να λύσει ένα δύσκολο μαθηματικό πρόβλημα και θα περιγράψει κάθε βήμα της διαδρομής του, μερικές φορές μιλώντας στον εαυτό του για χιλιάδες λέξεις καθώς επιχειρεί διάφορες προσεγγίσεις για το ερώτημα. «Πρέπει λοιπόν να βρω τον λιγότερο περιττό πρώτο παράγοντα του 20198 + 1. Χμμ, αυτό φαίνεται αρκετά σύνθετο, αλλά νομίζω ότι μπορώ να το αναλύσω βήμα-βήμα», αρχίζει το μοντέλο, δημιουργώντας 2.000 λέξεις ανάλυσης πριν καταλήξει, σωστά, στο συμπέρασμα ότι η απάντηση είναι 97.
Το άνοιγμα της Alibaba δεν είναι τυχαίο, λέει ο Eiso Kant, συνιδρυτής της Poolside, μιας εταιρείας με έδρα την Πορτογαλία που κατασκευάζει ένα εργαλείο τεχνητής νοημοσύνης για προγραμματιστές. Τα κινεζικά εργαστήρια διεξάγουν μια μάχη για το ίδιο ταλέντο με την υπόλοιπη βιομηχανία, σημειώνει. «Αν είσαι ερευνητής που σκέφτεται να μετακομίσει στο εξωτερικό, ποιο είναι το μόνο πράγμα που δεν μπορούν να σου δώσουν τα δυτικά εργαστήρια; Δεν μπορούμε να ανοίξουμε τα πράγματά μας πια. Κρατάμε τα πάντα κλειδωμένα, λόγω της φύσης του αγώνα δρόμου στον οποίο βρισκόμαστε». Ακόμα και αν οι μηχανικοί των κινεζικών εταιρειών δεν είναι οι πρώτοι που ανακαλύπτουν μια τεχνική, είναι συχνά οι πρώτοι που τη δημοσιεύουν, λέει ο κ. Kant. «Αν θέλετε να δείτε κάποια από τις μυστικές τεχνικές να βγαίνουν στη φόρα, ακολουθήστε τους Κινέζους ερευνητές ανοιχτού κώδικα. Δημοσιεύουν τα πάντα και κάνουν καταπληκτική δουλειά». Το έγγραφο που συνόδευσε την έκδοση της v3 ανέφερε 139 συγγραφείς με ονοματεπώνυμο, σημειώνει ο κ. Lane. Μια τέτοια αναγνώριση μπορεί να είναι πιο ελκυστική από το να μοχθούν στην αφάνεια όπως συμβαίνει στα αμερικανικά εργαστήρια.
Η αποφασιστικότητα της αμερικανικής κυβέρνησης να σταματήσει τη ροή προηγμένης τεχνολογίας προς την Κίνα έκανε τη ζωή των Κινέζων ερευνητών στην Αμερική λιγότερο ευχάριστη. Το πρόβλημα δεν είναι μόνο ο διοικητικός φόρτος που επιβάλλουν οι νέοι νόμοι που αποσκοπούν στο να κρατήσουν μυστικές τις τελευταίες καινοτομίες. Συχνά υπάρχει και μια ασαφής ατμόσφαιρα καχυποψίας. Οι κατηγορίες για κατασκοπεία εκτοξεύονται ακόμα και σε κοινωνικές εκδηλώσεις.
Το μεγάλο αφεντικό
Το όλο εγχείρημα στην Κίνα έχει και τα μειονεκτήματά του. Για παράδειγμα, αν ρωτήσετε το DeepSeek v3 για την Ταϊβάν, το μοντέλο αρχίζει να εξηγεί ότι πρόκειται για ένα νησί στην Ανατολική Ασία «επίσημα γνωστό ως Δημοκρατία της Κίνας». Αλλά αφού έχει συνθέσει μερικές προτάσεις προς αυτή την κατεύθυνση, σταματάει μόνο του, διαγράφει την αρχική του απάντηση και προτείνει κοφτά: «Ας μιλήσουμε για κάτι άλλο».
Τα κινεζικά εργαστήρια είναι πιο διαφανή από την κυβέρνησή τους, εν μέρει επειδή θέλουν να δημιουργήσουν ένα οικοσύστημα επιχειρήσεων με επίκεντρο την τεχνητή νοημοσύνη τους, το οποίο έχει κάποια εμπορική αξία, δεδομένου ότι οι εταιρείες που βασίζονται στα μοντέλα ανοικτού κώδικα μπορεί τελικά να πειστούν να αγοράσουν προϊόντα ή υπηρεσίες από τους δημιουργούς τους. Αποφέρει επίσης ένα στρατηγικό όφελος για την Κίνα, καθώς δημιουργεί συμμάχους στη σύγκρουσή της με την Αμερική για την τεχνητή νοημοσύνη.
Οι κινεζικές επιχειρήσεις φυσικά και προτιμούν να βασίζονται σε κινεζικά μοντέλα, δεδομένου ότι δεν χρειάζεται να ανησυχούν ότι νέες απαγορεύσεις ή περιορισμοί θα μπορούσαν να τις αποκόψουν από την υποκείμενη πλατφόρμα. Γνωρίζουν επίσης ότι είναι απίθανο να πέσουν θύμα των απαιτήσεων λογοκρισίας στην Κίνα, τις οποίες τα δυτικά μοντέλα δεν θα λάμβαναν υπόψη τους. Για εταιρείες όπως η Apple και η Samsung που επιθυμούν να ενσωματώσουν εργαλεία τεχνητής νοημοσύνης στις συσκευές που πωλούν στην Κίνα, οι τοπικοί συνεργάτες είναι απαραίτητοι, σημειώνει ο Francis Young, επενδυτής τεχνολογίας με έδρα τη Σαγκάη. Επιπλέον, ακόμα και ορισμένες επιχειρήσεις στο εξωτερικό έχουν συγκεκριμένους λόγους να χρησιμοποιούν κινεζικά μοντέλα: Το Qwen διαπνέεται σκόπιμα από ευχέρεια σε «μικρές» γλώσσες όπως τα Ουρντού και τα Μπενγκάλι, ενώ τα αμερικανικά μοντέλα εκπαιδεύονται χρησιμοποιώντας κυρίως αγγλικά δεδομένα. Έπειτα υπάρχει το τεράστιο πλεονέκτημα του χαμηλότερου κόστους λειτουργίας των κινεζικών μοντέλων.
Αυτό δεν σημαίνει απαραίτητα ότι τα κινεζικά μοντέλα θα σαρώσουν τον κόσμο. Η αμερικανική τεχνητή νοημοσύνη εξακολουθεί να έχει δυνατότητες που οι αντίπαλοί της στην Κίνα δεν μπορούν ακόμη να φτάσουν. Ένα ερευνητικό πρόγραμμα της Google παραδίδει το πρόγραμμα περιήγησης ενός χρήστη στο διαδίκτυο στο chatbot Gemini, δημιουργώντας την προοπτική της αλληλεπίδρασης «πρακτόρων» τεχνητής νοημοσύνης με το διαδίκτυο. Τα chatbots της Anthropic και της OpenAI δεν θα σας βοηθήσουν απλώς να γράψετε κώδικα, αλλά θα τον εκτελούν και για εσάς. Η Claude θα κατασκευάζει και θα φιλοξενεί ολόκληρες εφαρμογές. Η βήμα-βήμα συλλογιστική δεν είναι ο μόνος τρόπος επίλυσης πολύπλοκων προβλημάτων. Αν ρωτήσετε τη συμβατική έκδοση του ChatGPT την παραπάνω μαθηματική ερώτηση, για να βρει την απάντηση, γράφει ένα απλό πρόγραμμα.
Σύμφωνα με τον κ. Altman, ακόμα περισσότερες καινοτομίες βρίσκονται στα σκαριά. Σύντομα, αναμένεται να ανακοινώσει ότι η OpenAI κατασκεύασε «υπερ-πράκτορες διδακτορικού επιπέδου», οι οποίοι είναι εξίσου ικανοί με τους ανθρώπους εμπειρογνώμονες σε μια σειρά από διανοητικές εργασίες. Ο ανταγωνισμός που πιέζει την αμερικανική τεχνητή νοημοσύνη μπορεί να την ωθήσει σε μεγαλύτερα πράγματα.
© 2025 The Economist Newspaper Limited. All rights reserved. Άρθρο από τον Economist, το οποίο μεταφράστηκε και δημοσιεύθηκε με επίσημη άδεια από την www.powergame.gr. Το πρωτότυπο άρθρο, στα αγγλικά, βρίσκεται στο www.economist.com
Διαβάστε επίσης
Μήπως τελικά η φρενίτιδα για τα κρυπτονομίσματα στην Αμερική καταλήξει σε καταστροφή;
Σοκολάτα Ντουμπάι: Ποια είναι η γυναίκα πίσω από το viral γλυκό
Το παιχνίδι των ενεργειακών διαδρόμων, κινητικότητα στα Βαλκάνια







